分布式队列介绍
作为一种基础的抽象数据结构,队列被广泛应用在各类编程中。
大数据时代对跨进程、跨机器的通讯提出了更高的要求,和以往相比,分布式队列编程的运用几乎已无处不在。
目前使用最多的就是分布式消息队列,消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题。实现高性能,高可用,可伸缩和最终一致性架构。是大型分布式系统不可缺少的中间件。
目前在生产环境,使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ等,消息队列详细的比较(点击查看):
今天主要分享:提供一个系统性的思考方法,使读者能够将具体需求关联到分布式队列编程模型,具备进行分布式队列架构的能力,通过全方位的讲解,让读者能够快速识别工作中碰到的各种分布式队列编程模型。
分布式队列编程模型
模型篇从基础的需求出发,去思考何时以及如何使用分布式队列编程模型。
建模环节非常重要,因为大部分中高级工程师面临的都是具体的需求,接到需求后的第一个步骤就是建模。通过本篇的讲解,希望读者能够建立起从需求到分布式队列编程模型之间的桥梁。
1.何时选择分布式队列
通讯是人们最基本的需求,同样也是计算机最基本的需求。对于工程师而言,在编程和技术选型的时候,更容易进入大脑的概念是RPC、RESTful、Ajax、Kafka。在这些具体的概念后面,最本质的东西是“通讯”。
所以,大部分建模和架构都需要从“通讯”这个基本概念开始。当确定系统之间有通讯需求的时候,工程师们需要做很多的决策和平衡,这直接影响工程师们是否会选择分布式队列编程模型作为架构。从这个角度出发,影响建模的因素有四个:When、Who、Where、How。
2.When:同步通讯VS异步通讯
通讯的一个基本问题是:发出去的消息什么时候需要被接收到?这个问题引出了两个基础概念:“同步通讯”和“异步通讯”。
发出去的消息是否需要确认,如果不需要确认,更像是异步通讯,这种通讯有时候也称为单向通讯(One-Way Communication)。 如果需要确认,可以根据需要确认的时间长短进行判断。时间长的更像是异步通讯,时间短的更像是同步通讯。当然时间长短的概念是纯粹的主观概念,不是客观标准。 发出去的消息是否阻塞下一个指令的执行,如果阻塞,更像是同步,否则,更像是异步。 无论如何,工程师们不能生活在混沌之中,不做决定往往是最坏的决定。当分析一个通讯需求或者进行通讯构架的时候,工程师们被迫作出“同步”还是“异步”的决定。当决策的结论是“异步通讯”的时候,分布式队列编程模型就是一个备选项。
3.Who:发送者接收者解耦
在进行通讯需求分析的时候,需要回答的另外一个基本问题是:消息的发送方是否关心谁来接收消息,或者反过来,消息接收方是否关心谁来发送消息。如果工程师的结论是:消息的发送方和接收方不关心对方是谁、以及在哪里,分布式队列编程模型就是一个备选项。因为在这种场景下,分布式队列架构所带来的解耦能给系统架构带来这些好处:
无论是发送方还是接收方,只需要跟消息中间件通讯,接口统一。统一意味着降低开发成本。
在不影响性能的前提下,同一套消息中间件部署,可以被不同业务共享。共享意味着降低运维成本。
发送方或者接收方单方面的部署拓扑的变化不影响对应的另一方。解藕意味着灵活和可扩展。
4.Where:消息暂存机制
在进行通讯发送方设计的时候,令工程师们苦恼的问题是:如果消息无法被迅速处理掉而产生堆积怎么办、能否被直接抛弃?如果根据需求分析,确认存在消息积存,并且消息不应该被抛弃,就应该考虑分布式队列编程模型构架,因为队列可以暂存消息。
5.How:如何传递
对通讯需求进行架构,一系列的基础挑战会迎面而来,这包括:
可用性,如何保障通讯的高可用。
可靠性,如何保证消息被可靠地传递。
持久化,如何保证消息不会丢失。
吞吐量和响应时间。
跨平台兼容性。
除非工程师对造轮子有足够的兴趣,并且有充足的时间,采用一个满足各项指标的分布式队列编程模型就是一个简单的选择。
分布式队列编程定义
分布式队列编程模型包含三类角色:
发送者(Sender)
分布式队列(Queue)
接收者(Receiver)
发送者和接收者分别指的是生产消息和接收消息的应用程序或服务。
需要重点明确的概念是分布式队列,它是提供以下功能的应用程序或服务:
1. 接收“发送者”产生的消息实体;
2. 传输、暂存该实体;
3. 为“接收者”提供读取该消息实体的功能。特定的场景下,它当然可以是Kafka、RabbitMQ等消息中间件。但它的展现形式并不限于此,例如:
队列可以是一张数据库的表,发送者将消息写入表,接收者从数据表里读消息。
如果一个程序把数据写入Redis等内存Cache里面,另一个程序从Cache里面读取,缓存在这里就是一种分布式队列。
流式编程里面的的数据流传输也是一种队列。
典型的MVC(Model–view–controller)设计模式里面,如果Model的变化需要导致View的变化,也可以通过队列进行传输。这里的分布式队列可以是数据库,也可以是某台服务器上的一块内存。
抽象模型
最基础的分布式队列编程抽象模型是点对点模型,其他抽象构架模型居于改基本模型上各角色的数量和交互变化所导致的不同拓扑图。具体而言,不同数量的发送者、分布式队列以及接收者组合形成了不同的分布式队列编程模型。记住并理解典型的抽象模型结构对需求分析和建模而言至关重要,同时也会有助于学习和深入理解开源框架以及别人的代码。
1.点对点模型(Point-to-point)
基础模型中,只有一个发送者、一个接收者和一个分布式队列。如下图所示:

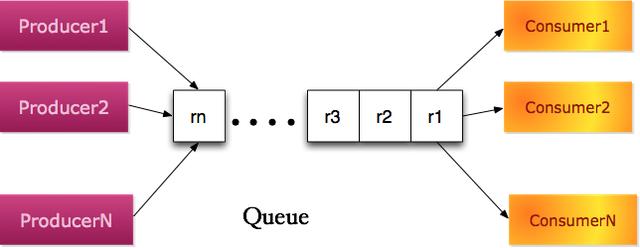
2.生产者消费者模型(Producer–consumer)
如果发送者和接收者都可以有多个部署实例,甚至不同的类型;但是共用同一个队列,这就变成了标准的生产者消费者模型。在该模型,三个角色一般称之为生产者(Producer)、分布式队列(Queue)、消费者(Consumer)。
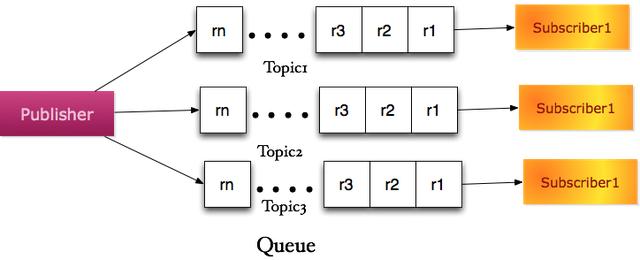
3.发布订阅模型(PubSub)
如果只有一类发送者,发送者将产生的消息实体按照不同的主题(Topic)分发到不同的逻辑队列。每种主题队列对应于一类接收者。这就变成了典型的发布订阅模型。在该模型,三个角色一般称之为发布者(Publisher),分布式队列(Queue),订阅者(Subscriber)。
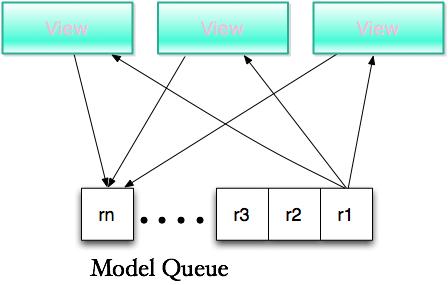
4.MVC模型
如果发送者和接收者存在于同一个实体中,但是共享一个分布式队列。这就很像经典的MVC模型。
5.编程模型
为了让读者更好地理解分布式队列编程模式概念,这里将其与一些容易混淆的概念做一些对比 。
分布式队列模型编程和异步编程
分布式队列编程模型的通讯机制一般是采用异步机制,但是它并不等同于异步编程。
首先,并非所有的异步编程都需要引入队列的概念,例如:大部分的操作系统异步I/O操作都是通过硬件中断( Hardware Interrupts)来实现的。
其次,异步编程并不一定需要跨进程,所以其应用场景并不一定是分布式环境。
最后,分布式队列编程模型强调发送者、接收者和分布式队列这三个角色共同组成的架构。这三种角色与异步编程没有太多关联。
分布式队列模式编程和流式编程
随着Spark Streaming,Apache Storm等流式框架的广泛应用,流式编程成了当前非常流行的编程模式。但是本文所阐述的分布式队列编程模型和流式编程并非同一概念。
首先,本文的队列编程模式不依赖于任何框架,而流式编程是在具体的流式框架内的编程。
其次,分布式队列编程模型是一个需求解决方案,关注如何根据实际需求进行分布式队列编程建模。
流式框架里的数据流一般都通过队列传递,不过,流式编程的关注点比较聚焦,它关注如何从流式框架里获取消息流,进行map、reduce、 join等转型(Transformation)操作、生成新的数据流,最终进行汇总、统计。
 已专注服务器托管十二年
已专注服务器托管十二年
 用心服务每一位客户
用心服务每一位客户
 7x24小时服务
7x24小时服务
 一站式全方位服务
一站式全方位服务

 关注微信公众号
关注微信公众号
7x24小时服务热线

 京公网安备 11010802021392号
京公网安备 11010802021392号