网站被恶意镜像,这个问题应该是所有草根站长最苦恼的问题,也是最深恶痛疾的事情。为了让大家对恶意镜像有一个清晰的认识,所以 leso99 特意在网络上收集整理一些关于恶意镜像的知识(如恶意镜像定义、危害与影响、防止镜像方法等)跟大家分享一下。
.jpg)
什么是恶意镜像?
恶意镜像,也叫恶意克隆,恶意解析,是指有人通过域名A记录直接解析别人IP地址,从而得到一个在访问者眼中完全相同网站的过程。其工作原理基本上是这样子的:有用户访问镜像站点时,程序就会来正版的站点查询数据,并修改相关链接然后呈献给用户,实质上还是在读取原站的数据。
网站被恶意镜像对有什么影响?
恶意镜像者意图通过自己有一定权重的域名进行威压,让搜索引擎对刚刚成立的网站产生迷惑,对同时存在和解析的两个域名分不清真假,不知如何抉择。有的搜索引擎技术比较成熟,可以分清真假,但是也有部分搜索引擎傻傻地分不清楚,有可能会选择恶意者的域名,同时删去原站长的域名。
至于恶意者得手之后会做些什么?我们无法推测,但是无论如何都不会是对我们有利的。千万不要因为镜像网站给我们带来的一些流量而庆幸,因为带来流量的同时也会带走你的用户,在搜索引擎迷惑的同时,用户也会无所适从,不知道哪个是真,哪个是假。如果恶意者域名或者其它部分含有敏感不健康的信息,也可能会导致受害者IP被封掉。
如何查看自己的网站是否被别人镜像?
在搜索引擎中限定搜索范围在自己网站的完整标题中(PS:查看自己站点首页源码,其中
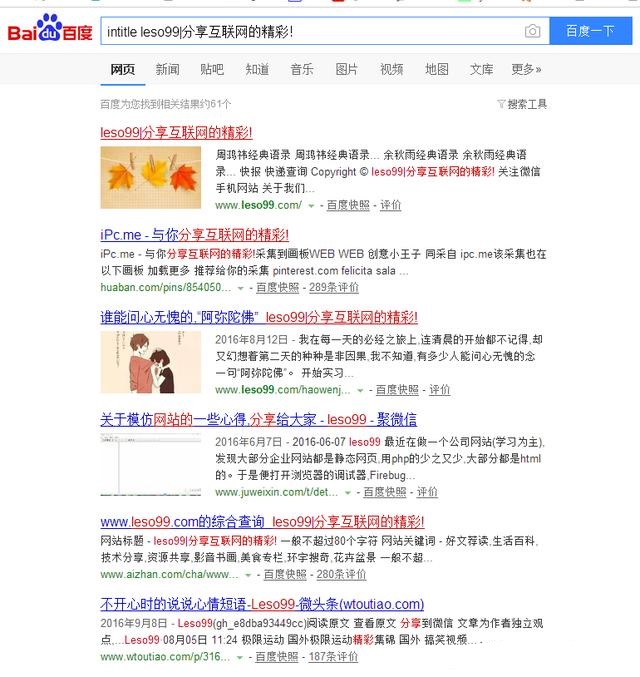
从上图搜索结果中可以看出,有几个跟我们站点标题一模一样的,但是域名却不是我们的,说明leso99|分享互联网的精彩!已经被恶意镜像了。
网站被恶意镜像怎么办?
网络上已经有很多大神分享了如何防止网站被恶意镜像的办法,现在就推荐几种leso99测试真正有效的防镜像方法,具体选择哪种方法就请大家根据自己的情况自由选择吧。
方法一:借助img的oneerror事件防恶意镜像
1、WordPress站点
将以下代码添加到主题functions.php文件最后一个?>即可。其他类似js防镜像方法可以不用了,不过用了也不会冲突。
●add_action('wp_head','deny_mirrored_websites');
●function deny_mirrored_websites(){
●$currentDomain = 'leso99." + "com';
●echo '<img style="display:none" src=" " onerror='var str1="' do_action="loca" alt="" />';
●}
以上代码来自张戈博客,其中,'leso99." + "com'需要自行修改成自己的域名即可,带有www的可以修改成"www." + "leso99" + ".com"
2、HTML通用站点
将以下代码添加到网站的和之间即可,WP一般为header.php文件,其他建站程序请自行搞定,这个版本适合任何网页。
●<img style="display:none" src=" " onerror='var currentDomain="leso99." + "com"; var str1=currentDomain; str2="docu"+"ment.loca"+"tion.host"; str3=eval(str2) ;if( str1!=str3 ){ do_action = "loca" + "tion." + "href = loca" + "tion.href" + ".rep" + "lace(docu" +"ment"+".loca"+"tion.ho"+"st," + "currentDomain" + ")";eval(do_action) }' alt="" />
以上代码来自张戈博客,其中,'leso99." + "com'需要自行修改成自己的域名即可,带有www的可以修改成"www." + "leso99" + ".com"
方法二:通过禁止某些User Agent特征防恶意镜像
1、PHP通用版
将以下代码加入到PHP网站根目录的index.php的
●/**
●* PHP通用版 禁止UA为空或含有PHP的请求 By 张戈博客
●* 原文地址:http://zhangge.net/5101.html
●**/
●$ua = $_SERVER['HTTP_USER_AGENT'];
●if(!$ua || preg_match('/PHP/i', $ua)) {
●header("Content-type: text/html; charset=utf-8");
●die('请勿采集本站,因为采集的站长木有小JJ!');
●}
2、WP专用版
将以下代码添加到主题functions.php文件最后一个?>即可。
●/**
●* WordPress 禁止UA为空或含有PHP的请求 By 张戈博客
●* 原文地址:http://zhangge.net/5101.html
●**/
●if(!is_admin()) {
●add_action('init', 'deny_mirrored_request', 0);
●}
●function deny_mirrored_request()
●{
●$ua = $_SERVER['HTTP_USER_AGENT'];
●if(!$ua || preg_match('/PHP/i', $ua)) {
●header("Content-type: text/html; charset=utf-8");
●wp_die('请勿采集本站,因为采集的站长木有小JJ!');
●}
●}
3、Nginx服务器版本
将以下规则加入到nginx的vhost当中 的配置文件的第一个location 之前,然后重载Nginx即可。
●if ($http_user_agent ~* "PHP") {
●return 403;
●}
总结一下
根据leso99导航使用情况来看,建议同时使用方法一和方法二,这样可以在禁止UA某些特征防止镜像失效的情况下,还可以通过借助img的oneerror事件防恶意镜像。最后强调一下,这些方法目前都是有效的,但是正所谓“道高一尺魔高一丈”,谁也无法保证这些方法能够长期有效。所以最有效的方法还是努力经营好自己的网站,把权重、流量、名气做上去,这样才能达成“一直被模仿,但从未被超越”的目标,到那时也就不怕什么恶意镜像了。
拓展延伸:
如果想通过禁止某些User Agent特征,同时达成防主流采集、垃圾爬虫、部分SQL注入和防网站被恶意镜像,可以通过以下方法实现。
PS:以下三个方法是上文“通过禁止某些User Agent特征防恶意镜像”的拓展延伸,所以只能二选一,不能同时使用。
特别声明:以下三个方法的代码来自(或修改自)张戈博客的《服务器反爬虫攻略:Apache/Nginx/PHP禁止某些User Agent抓取网站》。
1、Ngnix代码
进入到nginx安装目录下的conf目录,将如下代码保存为agent_deny.conf。
cd /usr/local/nginx/conf
vim agent_deny.conf
●#禁止Scrapy等工具的抓取
●if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
●return 403;
●}
●#禁止指定UA及UA为空的访问
●if ($http_user_agent ~ ' PHP|FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|
CoolpadWebkit|Java|Feedly|UniversalFeedParser|
ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-
urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|
EasouSpider|Ezooms|^$"') {
●return 403;
●}
●#禁止非GET|HEAD|POST方式的抓取
●if ($request_method !~ ^(GET|HEAD|POST)$) {
●return 403;
●}
然后,在网站相关配置中的location / { 之后插入如下代码:
●include agent_deny.conf;
如张戈博客的配置:
●[marsge@Mars_Server ~]$ cat /usr/local/nginx/conf/zhangge.conf
●location / {
●try_files $uri $uri/ /index.php?$args;
●#这个位置新增1行:
●include agent_deny.conf;
●rewrite ^/sitemap_360_sp.txt$ /sitemap_360_sp.php last;
保存后,执行如下命令,平滑重启nginx即可:
●/usr/local/nginx/sbin/nginx -s reload
2、PHP代码
将如下代码放到PHP网站根目录index.php中的第一个
●//获取UA信息
●$ua = $_SERVER['HTTP_USER_AGENT'];
●//将恶意USER_AGENT存入数组
●$now_ua = array('PHP','FeedDemon ','BOT/0.1 (BOT for JCE)'
,'CrawlDaddy ','Java','Feedly','UniversalFeedParser','ApacheBench
','Swiftbot','ZmEu','Indy Library','oBot','jaunty','YandexBot','AhrefsBot',
'MJ12bot','WinHttp','EasouSpider','HttpClient','Microsoft URL Control',
'YYSpider','jaunty','Python-urllib','lightDeckReports Bot');
●//禁止空USER_AGENT,dedecms等主流采集程序都是空USER_AGENT,部分sql注入工具也是空USER_AGENT
●if(!$ua) {
●header("Content-type: text/html; charset=utf-8");
●wp_die('请勿采集本站,因为采集的站长木有小JJ!');
●}else{
●foreach($now_ua as $value )
●//判断是否是数组中存在的UA
●if(eregi($value,$ua)) {
●header("Content-type: text/html; charset=utf-8");
●wp_die('请勿采集本站,因为采集的站长木有小JJ!');
●}
●}
3、WordPress专用版
将以下代码添加到主题functions.php文件最后一个?>即可。
●if(!is_admin()) {
●add_action('init', 'deny_mirrored_request', 0);
●}
●function deny_mirrored_request()
●{
●//获取UA信息
●$ua = $_SERVER['HTTP_USER_AGENT'];
●//将恶意USER_AGENT存入数组
●$now_ua = array('PHP','FeedDemon ','BOT/0.1
(BOT for JCE)','CrawlDaddy ','Java','Feedly',
'UniversalFeedParser','ApacheBench',
'Swiftbot','ZmEu','Indy Library','oBot','jaunty',
'YandexBot','AhrefsBot','MJ12bot','WinHttp',
'EasouSpider','HttpClient','Microsoft
URL Control','YYSpider','jaunty','Python-urllib',
'lightDeckReports Bot');
●//禁止空USER_AGENT,dedecms等主流采集程序都是空USER_AGENT,部分sql注入工具也是空USER_AGENT
●if(!$ua) {
●header("Content-type: text/html; charset=utf-8");
●wp_die('请勿采集本站,因为采集的站长木有小JJ!');
●}else{
●foreach($now_ua as $value )
●//判断是否是数组中存在的UA
●if(eregi($value,$ua)) {
●header("Content-type: text/html; charset=utf-8");
●wp_die('请勿采集本站,因为采集的站长木有小JJ!');
●}
●}
●}
 已专注服务器托管十二年
已专注服务器托管十二年
 用心服务每一位客户
用心服务每一位客户
 7x24小时服务
7x24小时服务
 一站式全方位服务
一站式全方位服务

 关注微信公众号
关注微信公众号
7x24小时服务热线

 京公网安备 11010802021392号
京公网安备 11010802021392号