缓存与消息队列有一些共同特点。
这两项技术都是非常强大的工具,因而广为流行。使用Memcached或者是一个消息队列,不是为了实现一个有趣的协议而与其他的工具进行交互,而是为了编写优雅的服务来解决特定的问题。
这两项技术解决的问题通常是机构内部特有的问题。我们通常无法仅从外界就得知一个特定的网站或服务使用了哪种缓存、哪种消息队列以及哪种负载分配工具。
尽管HTTP和SMTP这样的工具都是针对一个特定的负载设计的(HTTP针对超文本文档,SMTP针对电子邮件消息),但是缓存和消息队列是无需了解它们所需要传输的数据的。
这篇文章会介绍各个工具要解决的问题,解释使用相关服务来解决问题的方法,并且给出一些在Python中使用有关工具的提示。
下面说第一个重要的点就是Memcached,Memcached是内存缓存守护进程。Memcached将安全它的服务器的空闲RAM与一个很大的近期最少使用(LRU)的缓存结合使用。
之后我们会说Memcached的实现,实现中我们可以学习到一个重要的现代网络概念--分区。
使用Memcached的实际步骤是非常简单的:
在每台拥有空闲内存的服务器上都运行一个Memcached守护进程。
将所有Memcached守护进程的IP地址与端口号列出,并将该列表发送给所有将要使用Memcached的客户端。
客户端程序现在可以访问一个组织级的速度极快的键值缓存,它就像是所有服务器之间共享的一个巨大的Python字典。这个缓存是基于LRU的。如果有些项长时间没有被访问的话,就会将这些项丢弃,为新访问的项挪出空间,并记录被频繁访问的项。
下面给出一段代码,这段代码展示了在Python中使用Memcached的基本模式。在进行一个人工构造的花销很大的整数平方操作面前,代码会首先检查Memcached中是否已经保存了之前计算过的答案。如果没有的话,就会进行计算,并将答案放入缓存中。然后返回答案。
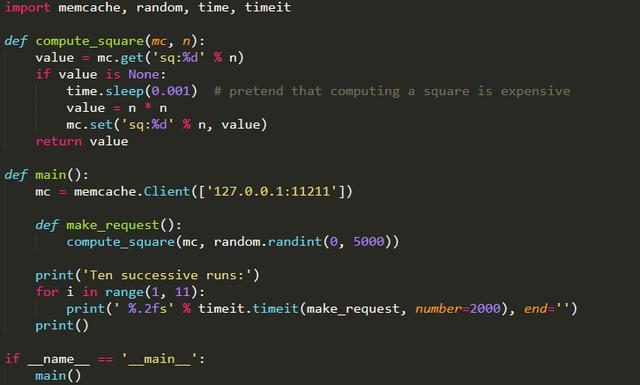
要运行这个例子,需要在机器的11211端口上运行Memcached守护进程。上述代码是给一个花销很大的操作加速。程序从最开始的几百个请求来说,会以正常的速度来运行。第一次请求计算某个证书的平方式,会发现RAM中并没有存储过该整数的平方,因此必须进行计算。但是,随着程序的运行,就会开始不断遇到一些相同的整数,此时程序会发现缓存中已经存储了一些证书的平方,从而加快了程序的运行速度。
当Memcached存满之后,速度就不会再有显著提升了。
下面说一下Memcached存在的问题,Memcached只是一个缓存,它存储的内容是暂时的,它使用RAM作为存储介质。一点系统重启,那么所有内容将会丢失。
然后还要确保缓存返回的内容不能太旧,这样返回给用户的数据才是精确的。至于新旧程度,应该和具体的需要解决的问题来看。比如,银行系统,就需要实时更新。而新闻网站首页就可以到几分钟。
下面是解决脏数据的三个方法,确保能够在数据过时之后进行及时清理,永远不返回脏数据。
Memcached允许我们为了缓存中的每一项设置一个过期时间。到达这个时间,Memcached会负责悄悄将这些项丢弃。
如果能够建立从信息标示到缓存中包含该标示的键的映射,那么就可以在脏数据出现后主动移除这些缓存项。
当缓存中的记录不可用时,我们可以重写并使用新内容代替该条记录,而不是简单地移除记录。
下面说一下散列和分区,Memcached的设计阐明了许多其他种类的数据库中使用的一个重要原理。而我们也很可能会想在自己的架构中应用这一个原理。当Memcached客户端得到了包含多个Memcached实例的列表时,会根据每个键的字符串值的散列值对Memcached数据库进行分区,由计算出的散列值决定用Memcached集群中的哪台服务器来存储特定的记录。
为了充分利用可用的RAM,Memcached集群会只希望存储一次这个键值对。而为了加快服务的速度,它希望能够在避免冗余的同时避免不同服务器之间的协同操作或是各客户端之间的通信。
这里给出一个相同的稳定算法。这就是解决Memcached集群服务器上的记录同步问题。下面是研究这些单词在4个服务器上的分布规律。第一个算法试图将字母表分为4个大致平均的部分,并根据单词的首字母来分配键。另外两个则使用了散列算法。
运行之后会发现,散列算法会更加适合。这里只是一个实现的细节,在使用Memcached这样的数据库系统时通常可以将这一细节忽略。这些数据库系统的客户端内部就支持分区。
不过,如果我们需要自行设计能够自动将负载或数据分配带集群中结点的服务时,要令多个客户端对统一数据输入给出相同的分配结果的话,就会发现,在代码中使用散列算法是十分有用的。
下面说一下消息队列,消息队列协议允许我们发送可靠的数据块。协议将这样的数据块成为消息,而不是数据报。因为数据报这一概念是用来特指不可靠服务的。
消息队列有一个创新之处,在与TCP这样基于IP传输机制提供的点对点连接不同,使用消息队列的客户端之间可以设置各种各样的拓扑结构。消息队列有许多可能的应用场景。
在使用电子邮件在一个网站注册新的账号的时候,网站会立刻返回一个页面,告知请于电子邮件收件箱内查收邮件。网站通常将电子邮箱地址放入一个消息队列中,后台建立起一个用于发送的SMTP链接。
消息队列可以作为自定义远程调用(RPC)服务的基础。远程过程调用服务允许繁忙的前段服务器将一些困难的工作交给后端服务器来负责。
前端服务器可以将请求置于消息队列中,几十甚至几百个后端服务器会对该消息队列进行监听,后端服务器在处理完消息队列中的请求后会将响应返回给正在等待的前端服务器。
经常需要将一些大容量的事件数据作为小型的有效信息流集中存储在消息队列中并进行分析。在一些网站中,消息队列已经彻底代替了存储到本地硬盘中的日志系统以及syslog这样更古老的日志传输机制。
消息队列应用程序设计有一个重要特点,就是具有混合安排并匹配所有客户端与服务器或发布者与订阅者进程的能力。需要的是,他么都需要连接到同一个消息队列系统。
通常来说,所有信息队列都支持多种拓扑结构。
管道:队列的最直观映像。
发布者-订阅者:一个对多个有兴趣的推送。
请求-响应:大量轻量级线程。请求即响应。
上面最后一个是最为复杂的模式。不过也几乎是最强大的模式。能够在某台机器上大量运行的多个轻量级线程(比如网络前端服务器的许多线程)与数据库或文件服务器连接起来的一种很好的方式。数据库客户端或文件服务器有时需要被调用,代替前端服务器进行一些高负荷的运算。请求-响应模式很自然地适用与RPC机制,而且还提供了普通RPC系统没有提供的额外优点:许多消费者或者生产者都可以使用扇入或者扇出的工作模式绑定到同一个队列,而模式的不同对于客户端来说是不可见的。
下面说在Python中使用消息队列。最流行的消息队列被实现为独立的服务器。构建应用程序时我们为了完成各种任务选用的所有组件(比如生产者、消费者、过滤器以及RPC服务)都可以绑定到消息队列。并且互相不知道彼此的地址,甚至不知道彼此的身份。
AMQP协议是最常见的快语言消息队列协议实现之一。我们安装很多支持AMQP协议的开源服务器。
下面只是给出一个用蒙特卡洛算法方法来计算π的值的代码。消息传递的拓扑结构相当重要。
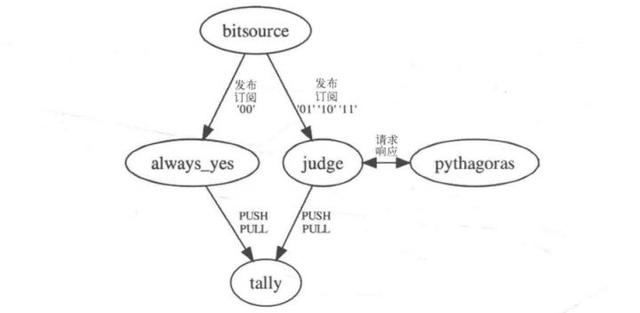
这个图便是估算π值的系统拓扑结构。
我们使用发布者-订阅者结构的消息队列。构建两个监听模块。
下面的代码包含了5个模块的拓扑结构,并且持续了30s。
pip install pyzmq
如果使用了操作系统默认提供的Python或者向Anaconda这样的独立安装板Python,这个包可能已经安装了。不过,无论哪种情况,都不会产生导入错误。
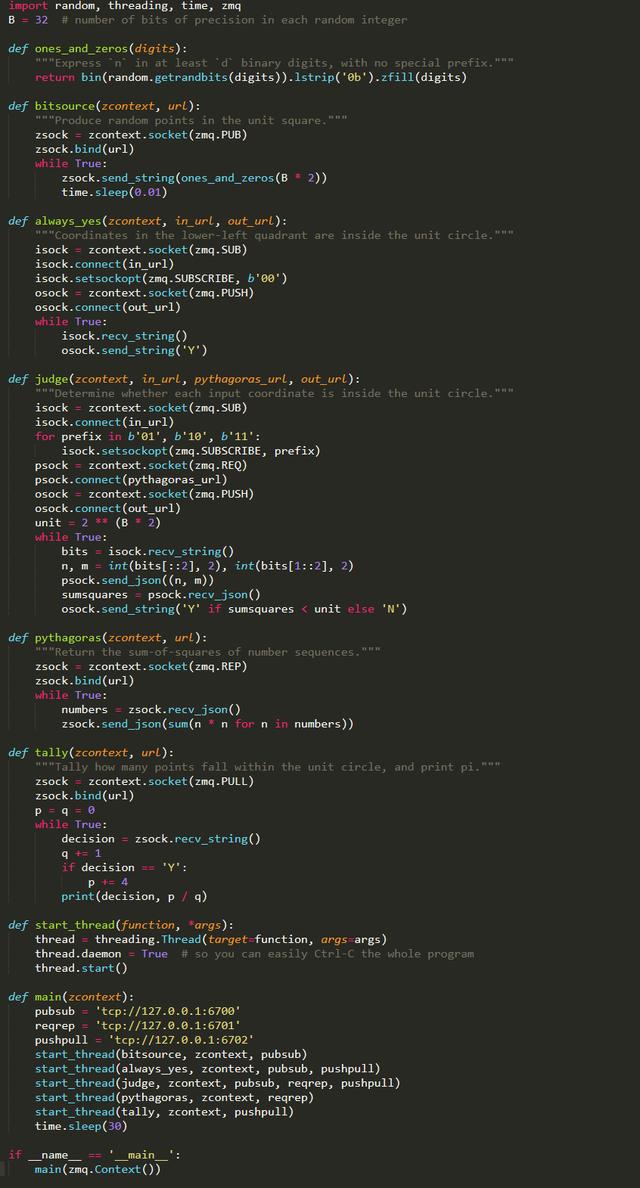
上述代码中的每一个线程都很小心地创建了各自的一个或者多个用于通信的套接字,原因是,试图让两个线程共享一个消息套接字并不安全。不过,多个线程之间确实共享了一个共同的上下文对象。
上述代码是比较简单的例子,我们需要保证消息的传输。在消息无法被处理的时需要将他们持久化保存。除此之外,还要进行一些流量控制。保证代码在速度较慢时也能够处理队列中处于等待状态的消息的数量。因此,我们通常需要使用一些更为复杂的模式。
 已专注服务器托管十二年
已专注服务器托管十二年
 用心服务每一位客户
用心服务每一位客户
 7x24小时服务
7x24小时服务
 一站式全方位服务
一站式全方位服务

 关注微信公众号
关注微信公众号
7x24小时服务热线

 京公网安备 11010802021392号
京公网安备 11010802021392号